
Pictograph Communication Technologies
Doctoral Research Newsletter #2Jaar 2: 2016
Leen Sevens, Centrum voor Computerlinguïstiek, KU Leuven
leen@ccl.kuleuven.be
My homepage
Promotor: Prof. Dr. Frank Van Eynde
Co-promotor: Dr. Vincent Vandeghinste
We're halfway there! This newsletter marks the very beginning of my third year as a PhD student. Ever wondered what would happen if you took a blender and added fifty litres of coffee, hundreds of hours of research, and thousands of tiny pictographs? Let's find out!
Just a quick reminder. My name is Leen Sevens, but people usually refer to me as "that girl who does that thing with those tiny, little images". At the Centre for Computational Linguistics (KU Leuven), we are building high-quality and fully automatic translation tools of text into pictographs and of pictographs into text. Our goal is to facilitate the accessibility of the Internet for users with reading and writing disabilities. For this purpose, various subtasks will have to be carried out. I will present these tasks and describe the progress that has already been made with respect to each one of them. Finally, I will discuss my dissemination activities.
Again, I would like to thank you for your interest and your support. If you have any questions or remarks, please do not hesitate to contact me. I'm always open to new ideas!

|
|
We are developing and improving the pictograph translation systems for the WAI-NOT communication platform. WAI-NOT is a Flemish non-profit organization that gives people with severe communication disabilities the opportunity to familiarize themselves with computers, the Internet, and social media. Their safe website environment offers an email client that makes use of the pictograph translation solutions. |
|
|
Additionally, we are developing English and Spanish versions of the tools within the Able-to-Include project. Able-to-Include seeks to improve the lives of people with Intellectual or Developmental Disabilities (ID). In order to be included in today’s society, it is becoming increasingly important to be able to use the current available technological tools. The number of apps is growing exponentially, but very few are really accessible to people with ID. Able-to-Include is creating a context-aware Accessibility Layer based on three key technologies that can improve the daily tasks of people with ID and help them interact with the Information Society. The integration of this Accessibility Layer with existing ICT tools will be tested in three different pilots in Spain, Belgium and the UK. The project runs until April 2017. |

The Text-to-Pictograph translation technology translates Dutch text into Beta or Sclera pictographs in order to facilitate the understanding of written text. Before I started my PhD, the Centre for Computational Linguistics had already developed a first version of this system. Meanwhile, behind the screens, I am developing all sorts of technological improvements that should make the original translation system even more user-friendly. Note that these improvements will not available in the Text-to-Pictograph translation demo until after extensive testing with the end users.

The automated spelling correction tool for people with Intellectual Disabilities was largely developed during my first year. Meanwhile, my colleagues and I have extensively described and evaluated the tool in a paper for an LREC workshop in Slovenia, which took place in May 2016. The system consists of a word variant generation and filtering step that is partially based on discovering phonetic similarities, followed by a completely novel approach to context-sensitive spelling correction. It's pretty cool, I can tell you that!

What does a user mean when he/she writes the (non-existing) word "wiekent"? Depending on the context, it could mean "wie kent" ("who knows", word splitting), "wieken" ("windmill sails", deletion of final "t"), "weekend" ("weekend", same pronunciation),... or maybe something else!
The end? Well, not really. My colleague Tom Vanallemeersch and I (accidentally) discovered that our unique approach toward spelling correction can also be applied in the context of modernisation of 17th-century Dutch. We're not kidding, we went from chatspeak to old Bible texts. 17th-century Dutch may seriously hamper diachronic linguistic research, as modern technologies are normally not trained on historical language. On top of that, spelling in historical texts is usually not very consistent at all. Are you curious to find out whether Tom and I will survive this challenging Shared Task? Stay tuned for the next newsletter!

Dutch input text in the Text-to-Pictograph translation system undergoes shallow linguistic analysis. Until now, linguistic analysis was limited to the word level. We improved the system by adding deep linguistic analysis on the sentence level.
First of all, we added Word Sense Disambiguation. Words usually have multiple senses. For instance, if someone is talking about a seal, is he/she referring to the marine animal or to an emblem which may be used as a means of authentication? For the Text-to-Pictograph translation system, it is important to know these differences, since the correct image must be generated within a specific context. For this reason, we introduced Ruben Izquierdo's Word Sense Disambiguation system in the translation process. This system makes sure that the most probable meaning of a word is chosen before translation into pictographs takes place.

What happens when we do not apply Word Sense Disambiguation and we pick the most frequent sense for each word? Then we will be baking waffles with "flower" ("bloem") instead of "flour" ("bloem")... How about a dandelion? Bon appétit!
In the original pictograph translation system, there was an almost one-on-one relation between the words of the input sentence and the pictographs in the output sequence. A long input sentence would correspond to a long pictograph translation. The order of the words in the original sentence remained largely unchanged in the pictograph sequence. And, as you can imagine, embedded relative clauses would often lead to unnecessary complexity. Given that many function words and grammatical characteristics are absent in the pictograph translation, the end users sometimes experienced difficulties in determining the meaning of the sequence. Our solution? Syntactic simplification! We cut the sentences into pieces, convert passive sentences into active ones, aim for Subject-Verb-Object (SVO) order, and so on. We were inspired by the guidelines of Klare Taal ("Clear Language) to create a list of challenging syntactic phenomena for our system to tackle. When such a phenomenon presents itself in the input sentence, it will be simplified by our engine before the conversion into pictographs takes place. The result? Shorter, readable pictograph sequences.
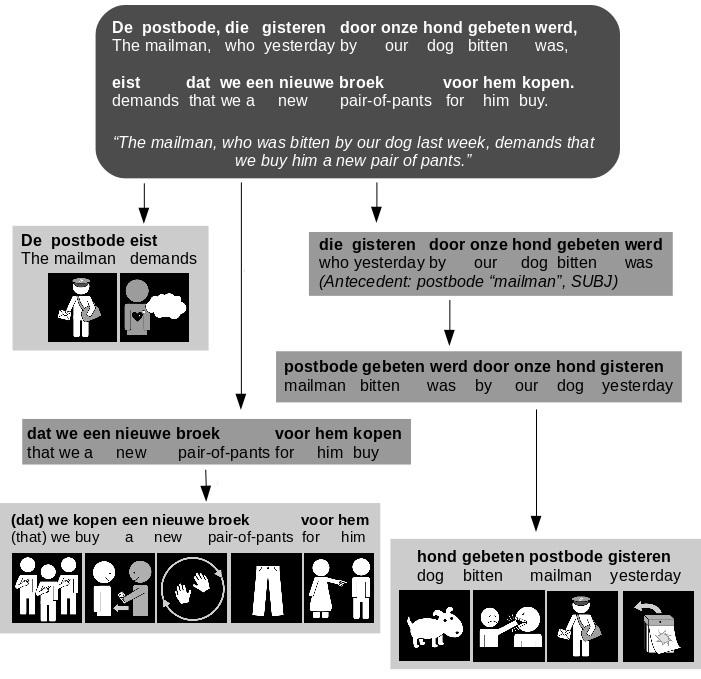
Simplification of a long, complex input sentence. The output consists of three pictograph sequences. Every sequence is written in Subject-Verb(-Object) order. The passive clause is converted into an active pictograph sequence. On top of that, the antecedent "postbode" ("mailman") is retrieved from the original mail clause.

The Pictograph-to-Text translation technology translates Beta or Sclera pictographs into Dutch text in order to facilitate the construction of written text. For a sneak peek behind the scenes, you can have a look at our demo here.

Last year, we developed the first version of our Pictograph-to-Text translation system. It searches for an optimal translation of pictographs into natural language by means of trigram language models, where possible. Not a bad attempt at all, but there is certainly room for improvement. First of all, thanks to the hard work of our MA student Adriaan Lemmens, we have been given the opportunity to explore the rule-based approach toward Pictograph-to-Text translation. The rule-based engine is based on a cascade of two grammars that were written in the Head-Driven Phrase Structure Grammar formalism and is developed and compiled in the LKB system. The main advantage of the rule-based system is that it is very likely to generate sentences that are grammatically correct. However, its recall is pretty low, and it is not able to deal with unexpected input. This year, I will also have a look at Recurrent Neural Networks, the absolute coolest form of Machine Learning. I can't wait to start overheating our computers!

Pictograph-to-Text translation.

The Pictograph-to-Text translation engine relies on pictograph input. I developed the first version of my pictograph hierarchy during my first year as a PhD student. Its structure is based on automated topic detection and frequency counts applied to emails that were sent by means of the WAI-NOT email client. This year, my pictograph hierarchy was made available on WAI-NOT and the Able to Include paplications. On top of that, we evaluated and discussed the interface with the end users. Ever since the new interface was launched, more and more pictograph-based messages are being composed and sent with the WAI-NOT email system. In more than 70% of the cases, the pictograph-based messages have a very clear communicative message. In the old system, nearly 70% of all pictograph-based messages were the result of random clicking.
Furthermore, we have merged our two dynamic pictograph prediction systems and created the ultimate pictograph prediction engine (that's not actually its real name). The prediction system suggests new pictographs to the users based on the pictographs that were already inserted.
We also created a Pictograph-to-Pictograph translation system, which allows Beta users to communicate with Sclera users, and vice versa. The world is in your hands!

This is an example of our interface. In this case, the user is browsing the "Home" > "Nature" > "Weather" level. This category contains all sorts of pictographs that are related to weather phenomena. By clicking the blue buttons, the user will return to the previous level in the pictograph hierarchy ("Nature"). The orange button brings the user back to the "Home" level.


In vitro evaluations of the tools
Statistical and manual evaluations were done for every (version of every) subcomponent that we have developed so far. This way, we can continue to measure the added value of future improvements.
In vivo evaluations of the users' experiences with the tools
We will assess the technology and its impact on the improvement of the user's abilities and their well-being. We are convinced that this approach is necessary to fine-tune our tools and adapt them to the users' needs. This year, I took part in two focus groups (small discussion groups) with our end users. The first session took place at Huize Eigen Haard in Aarschot. We evaluated the added value of Text-to-Pictograph translation in Facebook and Facebook Messenger. While the participants highly enjoyed accessing social media websites through language technology, they also argued that the pictograph translations were sometimes be a bit too complex for them. This is why we developed the simplification tool.
Our second session took place in Borgerstein in Sint-Katelijne-Waver. During our meeting, we evaluated the new pictograph hierarchy in the Pictograph-to-Text translation system. We discussed the communicative needs and the expectations of our participants and put the tool to the test during a hands-on session. Navigation in the pictograph hierarchy turned out to be surprisingly easy for our users. And although we expected our participants to claim that the interface contained too many pictographs, they assured us that they do not want their pictograph vocabulary to be limited. Intuitively, some of the participants discovered some of their favourite pictographs in the hierarchy. Of course, we expect that repeated use of the interface will lead to a better user experience.

In March 2016, our second Able to Include review meeting took place in Fundación Prodis in Madrid. Prodis is a daycare centre for people with Intellectual Disabilities. The youngsters learn, for instance, how to send emails by means of language technology.

Publications (in 2016)
Jaime Medina Maestro, Horacio Saggion, Ineke Schuurman, Leen Sevens, John O’Flaherty, Annelies De Vliegher and Jo Daems (2016). "Towards Integrating People with Intellectual Disabilities in the Digital World". In: Proceedings of the 7th International Workshop on Intelligent Environments Supporting Healthcare and Well-being (WISHWell’16). London, UK. [Download paper]
Leen Sevens, John J. O' Flaherty, Ineke Schuurman, Vincent Vandeghinste and Frank Van Eynde (2016). "E-Inclusion of Functionally Illiterate Users by the use of Language Technology". In: Proceedings of the 2nd Conference on Engineering4Society. Heverlee, Belgium. [Download paper]
Leen Sevens, Gilles Jacobs, Vincent Vandeghinste, Ineke Schuurman and Frank Van Eynde (2016). "Improving Text-to-Pictograph Translation Through Word Sense Disambiguation". In: Proceedings of the 5th Joint Conference on Lexical and Computational Semantics. Berlin, Germany. [Download paper]
Leen Sevens, Tom Vanallemeersch, Ineke Schuurman, Vincent Vandeghinste and Frank Van Eynde (2016). Automated Spelling Correction for Dutch Internet Users with Intellectual Disabilities. In: Proceedings of 1st Workshop on Improving Social Inclusion using NLP: Tools and Resources (ISI-NLP, LREC workshop). Portoroz, Slovenia, pp. 11-19. [Download paper]
Awards (in 2016)

Presentations (in 2016)
I have (still) been talking quite a lot! You may find all my presentations here.
Broader dissemination (in 2016)
March 2016 - Campuskrant (Leuven, België)
In March, I was in interviewed by Campuskrant (Campus Newspaper) of KU Leuven. This article appeared both online and in print in the March 2016 edition of Campuskrant. You can read the (Dutch) interview here.

December 2016 - Onderzoek in de Kijker (Faculteit Letteren) (Leuven, België)
The Faculty of Arts of KU Leuven interviewed me for "Onderzoek in de Kijker", which appeared in the December 2016 edition of our faculty's newsletter. You can read the (Dutch) interview here.

December 2016 - IEEE Potentials 36(1): 29-33
Vincent Vandeghinste, Ineke Schuurman and I were given the opportunity to write an article for IEEE Potentials, an international, scientific magazine for students and young professionals. Our text appeared in the thematic issue "The Hope of Assistive Technology".

